·
8 min
Self-Healing Locators: The End of Flaky Tests

Roman Kirchmeier - Autemos

A test that was green yesterday and red today, with nobody touching the code: that's a flaky test. As far back as 2017, Google found that roughly 16% of its ~4.2 million tests showed some flakiness (Micco/Google, 2017). Self-healing locators promise relief. They repair broken element selectors automatically when the user interface changes. This article explains why flaky tests happen, what they actually cost, how self-healing works under the hood, and where its honest limits lie.
TL;DR: Flaky tests burn measurable time. Atlassian puts the waste from test reruns alone at over 150,000 developer hours per year (Atlassian Engineering, 2025). Self-healing locators realistically fix ~70-85% of failures caused by UI changes, not all of them. What matters most is that every repair stays logged and auditable.

Figure 1: Self-healing locators store multiple signals per element instead of a single selector.
What are flaky tests and why do they happen?
A flaky test returns pass sometimes and fail other times, with identical code and unchanged behavior. Google measured back in 2017 that about 1.5% of all test runs were flaky and roughly 84% of pass-to-fail transitions involved a flaky test (Micco/Google, 2017). That's what makes them so insidious: they hide among real failures.
The causes are varied, but one pattern stands out. In UI tests, selectors break the moment the markup changes. A renamed CSS class, a new wrapper in the DOM, a generated ID: suddenly the test can't find its element anymore.
The most common breakage points
Brittle locators: XPath paths or CSS selectors tied to position or structure rather than stable attributes.
Timing: Asynchronous loads where the test moves faster than the application.
Test data: State that isn't cleanly reset, or shared environments.
Architecture: Race conditions, caching, unstable third-party systems.
Only the first category can be addressed directly by self-healing locators. That's an important distinction we'll return to.
What do flaky tests really cost?

Figure 4: Three sourced figures on the cost of flaky tests.
Flaky tests cost concrete developer time, not just frustration. Atlassian reports that reruns waste over 150,000 developer hours per year in the Jira backend alone, and that flakiness causes around 21% of frontend master build failures (Atlassian Engineering, 2025). Their infrastructure processes over 350 million test executions per day.
The problem is growing, not shrinking. Based on an analysis of more than ten million Bitrise builds, the share of mobile teams hitting flaky tests rose from 10% (2022) to 26% (2025) (SD Times/Bitrise, 2025). That figure comes from a single source and shows a trend, not a hard constant.
An industrial single-case study from TU Munich put the effort spent repairing flaky tests at up to 1.28% of developer time, roughly $2,250 per month for one team (IEEE/TU Munich, 2024). It's one data point, not an industry average, but it makes the pattern tangible.
The real damage isn't lost time, it's lost trust. Once a team learns to dismiss red tests as noise, the suite stops catching genuine regressions. Test maintenance is tightly bound to this trust problem, as we explore in our piece on reducing test maintenance with AI.
What are self-healing locators and how do they work?
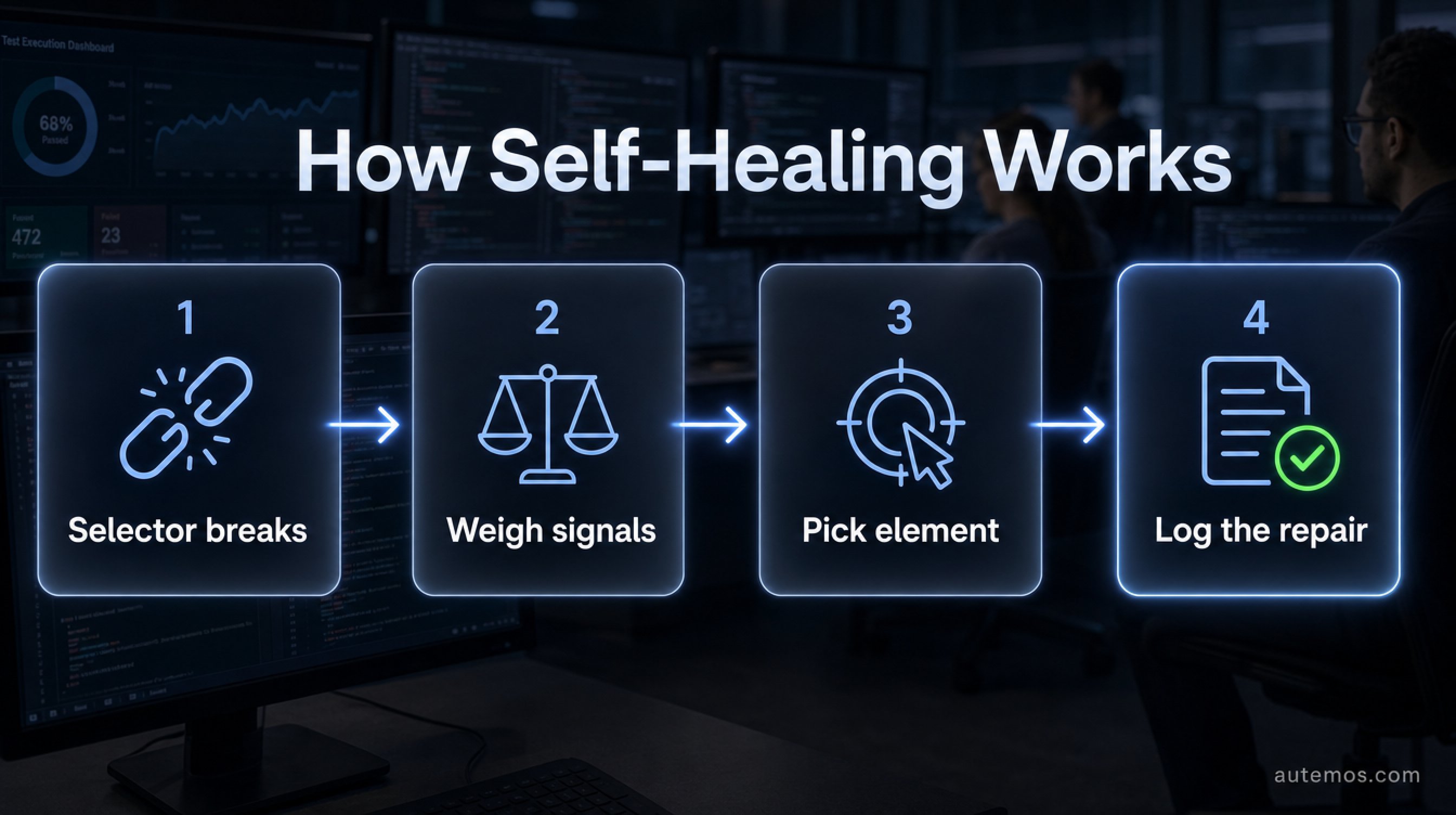
Figure 2: From a broken selector to a logged repair in four steps.
Self-healing locators are element selectors that repair themselves automatically when the original selector fails after a UI change. Instead of failing immediately, the mechanism re-identifies the intended element using several stored characteristics. This technique belongs to the broader field of AI test automation, which extends traditional scripts with adaptive logic.
At its core, the tool stores not just one selector at recording time, but a profile of multiple attributes.
What signals self-healing uses
Multiple attributes: ID, class, name, text content, ARIA role, position in the DOM tree.
Relative position: Proximity to stable neighboring elements or labels.
Visual cues: In some tools, the element's approximate location and appearance.
History: Which selectors worked in earlier runs.
When the primary selector breaks, the algorithm weights the remaining signals and picks the most likely candidate element. If it finds a reliable match, the test continues and the repaired selector is proposed for future runs.
In practice, we see the biggest payoff in broad, shallow suites with many click paths through frequently changing frontends. Where a frontend refactor would otherwise break hundreds of selectors at once, self-healing absorbs most of the impact.
How much do self-healing locators actually fix?

Figure 3: Only brittle locators are healable.
Realistically, self-healing locators fix about 70-85% of failures caused by UI changes, while the rest stems from data, timing, and architecture (Virtuoso QA, 2024). This range is more honest than the round marketing numbers floating around the market.
Vendors report maintenance reductions in the 80-95% range, but these numbers aren't comparable. mabl advertises "up to 95%", Functionize cites 85% less maintenance at 99.9% healing accuracy, and Virtuoso/DXC report 83% (Functionize; Virtuoso QA, 2024-25). Each figure came from different applications, suites, and measurement methods.
An aggregated "self-healing solves 90% of all problems" claim would be misleading. These numbers measure per-vendor maintenance effort, not the share of all flaky-test causes. Since only the locator category is healable, self-healing is by definition part of the solution. Anyone framing it otherwise is selling a promise the technology can't keep.
The remaining causes need other tools: better wait strategies against timing flakiness, clean test-data isolation, more stable architecture. Self-healing doesn't replace that work.
Why must self-healing be logged and auditable?
Self-healing without a log is a risk, not a feature. Repairs silently change what a test checks, and that's exactly where the danger lies. If the mechanism picks the wrong element, the test keeps passing while it's testing something other than intended. Trust in AI output is already strained: Google's DORA 2025 report shows developers often re-spend saved time verifying AI output (Google DORA, 2025).
A black-box repair undermines the very trust a test suite is supposed to deliver. That's why every heal needs a trail.
What a trustworthy self-healing solution logs
What broke: The original selector and the reason for the failure.
What was chosen: The new element along with a confidence score.
When and where: Timestamp, test run, environment.
Approval: A way for a human to confirm or reject the repair.
This is exactly where Autemos comes in. Self-healing locators in Autemos are logged, not black-box: every repair is recorded and can be approved by a human. For regulated industries like banking, this audit trail matters more than a high automation rate. If you can't prove why a test is green, you have a problem in an audit.
What flaky tests really cost
Source | Figure |
|---|---|
Google (ICST, 2017) | ~16% of 4.2M tests intermittently flaky |
Atlassian (2025) | 150,000+ developer hours per year lost to reruns |
Bitrise (2022 to 2025) | teams hitting flaky tests rose from 10% to 26% |
Self-healing (realistic) | covers roughly 70 to 85% of UI-driven failures |
Frequently asked questions
What's the difference between flaky tests and real failures?
A flaky test changes its result without any code or behavior change; a real failure reflects an actual regression. Google measured that roughly 84% of pass-to-fail transitions involved a flaky test (Micco/Google, 2017). The cleanest way to separate them is reruns combined with logging.
Do self-healing locators eliminate all flaky tests?
No. Self-healing only addresses failures from UI and locator changes, realistically about 70-85% of that category (Virtuoso QA, 2024). Flakiness from timing, test data, or architecture needs other solutions like better wait strategies and data isolation.
Are the 80-95% maintenance reductions credible?
They are vendor-specific and not comparable. mabl cites "up to 95%", Functionize 85%, Virtuoso/DXC 83% (Functionize, 2024-25). Each number came from different conditions, so read them as individual claims, not an industry benchmark.
Why does logging matter for self-healing?
Because a silent repair can change what a test checks without anyone noticing. Without a log, you risk green tests that test the wrong thing. An auditable trail is mandatory in regulated industries, as we detail in our piece on test maintenance with AI.
How big is the flaky-test problem really?
It's measurable and growing. Atlassian puts the waste at over 150,000 developer hours per year from reruns alone (Atlassian Engineering, 2025). Among mobile teams, the share affected rose from 10% to 26% between 2022 and 2025 (SD Times/Bitrise, 2025).
Conclusion
Flaky tests aren't a niche concern, they're a measurable cost problem: Google saw roughly 16% of all tests affected back in 2017, and Atlassian puts the waste at over 150,000 developer hours per year. Self-healing locators are a strong tool against this, but not a cure-all. They realistically repair 70-85% of UI-driven failures, while timing, data, and architecture demand their own answers.
The decisive point isn't the highest healing rate, it's traceability. A logged, human-approved repair protects trust in your suite. A black box erodes it. If you'd like to see what auditable self-healing looks like in practice, book a demo and have the audit trail shown on your own tests.


