·
9 min
GDPR-Compliant Test Data: Test Data Management in Regulated Industries

Roman Kirchmeier - Autemos

Real customer data in the test environment is convenient — and a serious data protection risk. In regulated industries, copying production data into test or QA systems can quickly breach the GDPR. This step-by-step guide shows how to provision test data that is both lawful and realistic enough for meaningful testing.
In brief: Personal production data in test or QA environments usually breaches the data-minimisation principle (Art. 5 GDPR). Synthetic or fully anonymised test data is lawful. Pseudonymised data, by contrast, remains personal data and stays in scope of the GDPR.

Figure 1: From risky production data to a lawful test environment – production data, anonymisation and synthetic data at a glance.
The problem: production data in testing is risky
For realistic testing, many teams simply pull a copy of the production database into the test environment. This usually conflicts with the data-minimisation principle in Article 5(1) GDPR, which limits personal data to what is necessary for the purpose (EUR-Lex).
Especially tricky: the Spanish data protection authority AEPD warns that pre-production and development environments are often less well protected than production — additional processors, different cloud providers and forgotten environments can make the risk even higher. The authority explicitly recommends generating test data artificially, that is, synthetically (AEPD, 2022).
Why "pseudonymised" does not mean "outside the GDPR"
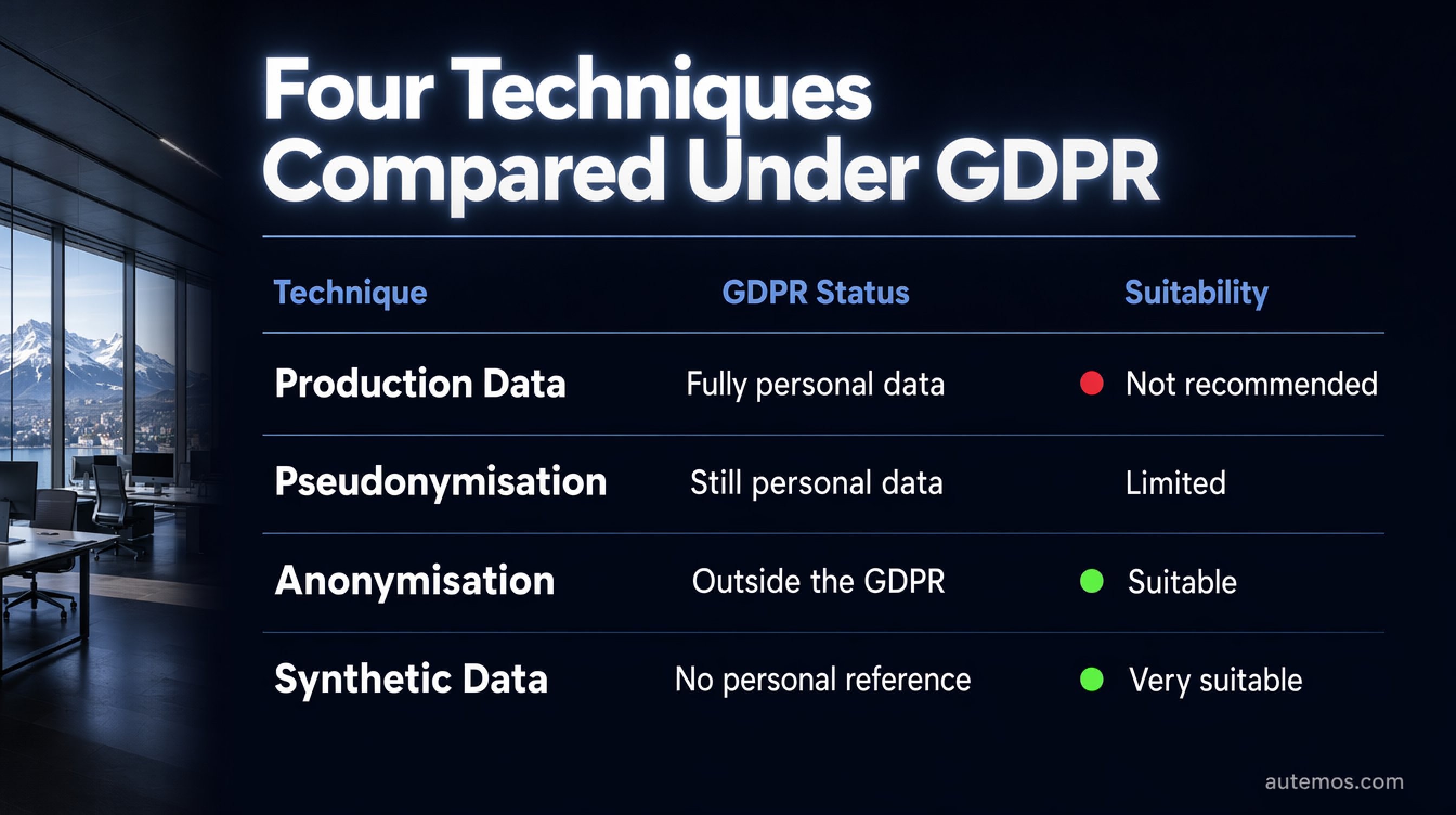
Figure 2: Four techniques compared under the GDPR – production data, pseudonymisation, anonymisation and synthetic data by status and testing suitability.
A common misconception: those who pseudonymise data often believe they are already outside the GDPR. That is wrong. Under Article 4(5) GDPR, pseudonymised data remains personal data as long as attribution is possible via separately kept additional information — all GDPR obligations continue to apply (EDPB, 2025).
Only true, irreversible anonymisation (Recital 26) takes data out of the GDPR's scope. The following table classifies the common techniques:
Technique | GDPR status | Suitability for testing |
|---|---|---|
Production data (cleartext) | Fully personal, high risk | Not recommended |
Pseudonymisation | Still personal data | Limited, with safeguards |
Anonymisation (irreversible) | Outside the GDPR | Suitable if realism is preserved |
Synthetic test data | No personal reference if generated correctly | Very suitable, recommended by authorities |
Step by step to GDPR-compliant test data

Figure 3: Six steps to GDPR-compliant test data – from taking stock through data minimisation and privacy by design to keeping evidence.
Here is how to build lawful test data management:
Step 1 – Take stock: Clarify which test and QA environments currently hold personal data and where it comes from.
Step 2 – Apply data minimisation: Reduce the data volume to what is necessary for each test.
Step 3 – Choose a technique: Prefer synthetic test data; where real reference is needed, anonymise irreversibly.
Step 4 – Preserve realism: Ensure test data reflects the structure, value ranges and edge cases of the real data, or the test loses its meaning.
Step 5 – Anchor privacy by design: Implement the requirements of Articles 25 and 32 GDPR technically, for example through access controls and automatic data masking during provisioning.
Step 6 – Keep evidence: Document that your test environments are free of unprotected production data — as part of your audit trail.
How Autemos supports the provisioning and masking of test data is shown on our feature page on test data handling.
Synthetic test data: the recommended route

Figure 4: Synthetic test data on the rise – its use in testing grew from 14% (2024) to around 25% (2025). Source: World Quality Report 2025-26, Capgemini.
Synthetic test data is artificially generated data that reproduces the statistical and structural properties of real data without representing real people. If it contains no personal data, it falls outside the scope of the GDPR — exactly the approach recommended by the AEPD.
The market is moving in this direction too: in the World Quality Report 2025-26, the use of synthetic data in testing rose from 14 percent (2024) to around 25 percent (2025); at the same time, 60 percent of respondents say they struggle with secure and scalable test data (Capgemini, 2025) — a vendor survey, but one that clearly shows the trend.
In client projects, we see that synthetic and anonymised test data not only reduces the data protection risk but also speeds up provisioning, because lengthy approval processes for real data fall away. The full regulatory frame is provided by the guide Testing in Regulated Industries; it becomes sector-specific in Test Automation in the Insurance Industry, where data migration and policy data are especially sensitive.
Frequently asked questions
May you use production data in test environments?
Usually not. Using personal production data in test or QA environments generally breaches the data-minimisation principle in Article 5 GDPR. Supervisory authorities recommend synthetic or irreversibly anonymised test data.
Is pseudonymised test data GDPR-compliant?
Pseudonymised data remains personal data and stays in scope of the GDPR, because re-identification is possible via separate additional information. It can only be used with extra safeguards — it is not the same as anonymous.
What is synthetic test data?
Synthetic test data is artificially generated data that reproduces the structure and statistical properties of real data without containing real people. If it has no personal reference, it falls outside the scope of the GDPR and is considered the preferred route for testing.
Does this apply in Switzerland too?
Yes, analogously. The revised Swiss Federal Act on Data Protection (revDSG) has applied since 1 September 2023 with no transition period (Swiss Confederation, 2023) and likewise enshrines privacy by design and by default as well as data protection impact assessments for high-risk processing.
Conclusion
Realistic testing and data protection are not mutually exclusive — if you design test data management deliberately. Production data does not belong unprotected in test or QA environments; synthetic and irreversibly anonymised data is the lawful route, while pseudonymised data remains in scope of the GDPR. Those who anchor data minimisation and privacy by design early reduce risk and speed up provisioning at the same time. If you want to set up your test data management across web, mobile, API and desktop in a GDPR-compliant way, talk to the Autemos team about your specific use case.


